
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Linear Regression
- jupytertheme
- ubuntu
- Git
- overfitting
- feature scaling
- Python
- 주피터노트북 커널 제거
- Machine Learning
- 모두를 위한 딥러닝
- 경사하강법
- 딥러닝
- MySQL
- pandas
- deep learning
- lol api
- deeplearning
- 주피터노트북
- GitHub
- 주피터노트북 커널 목록
- 회귀분석
- 주피터 노트북 테마
- 데이터분석
- random forest
- 주피터노트북 커널 추가
- 한빛미디어
- 주피터테마
- regression
- Udacity
- 나는리뷰어다2021
- Today
- Total
유승훈
Intro to machine learning - (7) Outliers 본문
Intro to machine learning - (7) Outliers
seunghuni96 2021. 1. 18. 17:55이번 강의에서는 이상치, Outlier에 대해 설명하고 있습니다.

Outliers, 이상치는 "평균적인 데이터의 패턴과 많이 다른 형태의 데이터"로 정의할 수 있습니다.
위의 데이터에서는 연두색으로 표시한 데이터를 이상치로 볼 수 있습니다. Outlier 하나 때문에 나머지 데이터를 잘 설명하는 Line C에서 Line A로 회귀선이 변화하는 것을 볼 수 있습니다. 이처럼 Outlier는 모델의 Error를 증가시키기도 하고, 설명력을 감소시킵니다. 회귀분석이나 분산분석같은 통계적인 기본가정들을 훼손할수도 있습니다.

Outlier가 생기는 이유에 대해서 이야기해보자면, 데이터를 수집, 입력, 샘플링하는 과정에서 발생할수도 있고, 별다른 이유없이 자연적으로 생기는 경우도 있습니다.
센서 오작동이나 데이터의 입력 오류처럼 단순하게 처리하고 넘어갈 수 있는 것들이 있고, 평소와는 아주 다른 상황에서 나온 데이터로 우리가 신경써서 살퍼보아야 하는 경우가 있습니다. 강의에서는 센서 오작동을 예로 들었는데, 보안 시스템, 불량제품 탐지처럼 센서 오작동을 그냥 넘길수 없는 분야도 있습니다.
과거의 데이터를 기반으로 새로운 데이터의 정상/비정상 여부를 판단하는 경우가 Outlier에 집중하는 분야입니다. 강의에서는 사기탐지를 예로 들었는데, 그 외에도 보안 시스템, 불량공정, 반도체, 자율주행 등에서도 이상치 탐지는 아주 중요하게 활용됩니다.
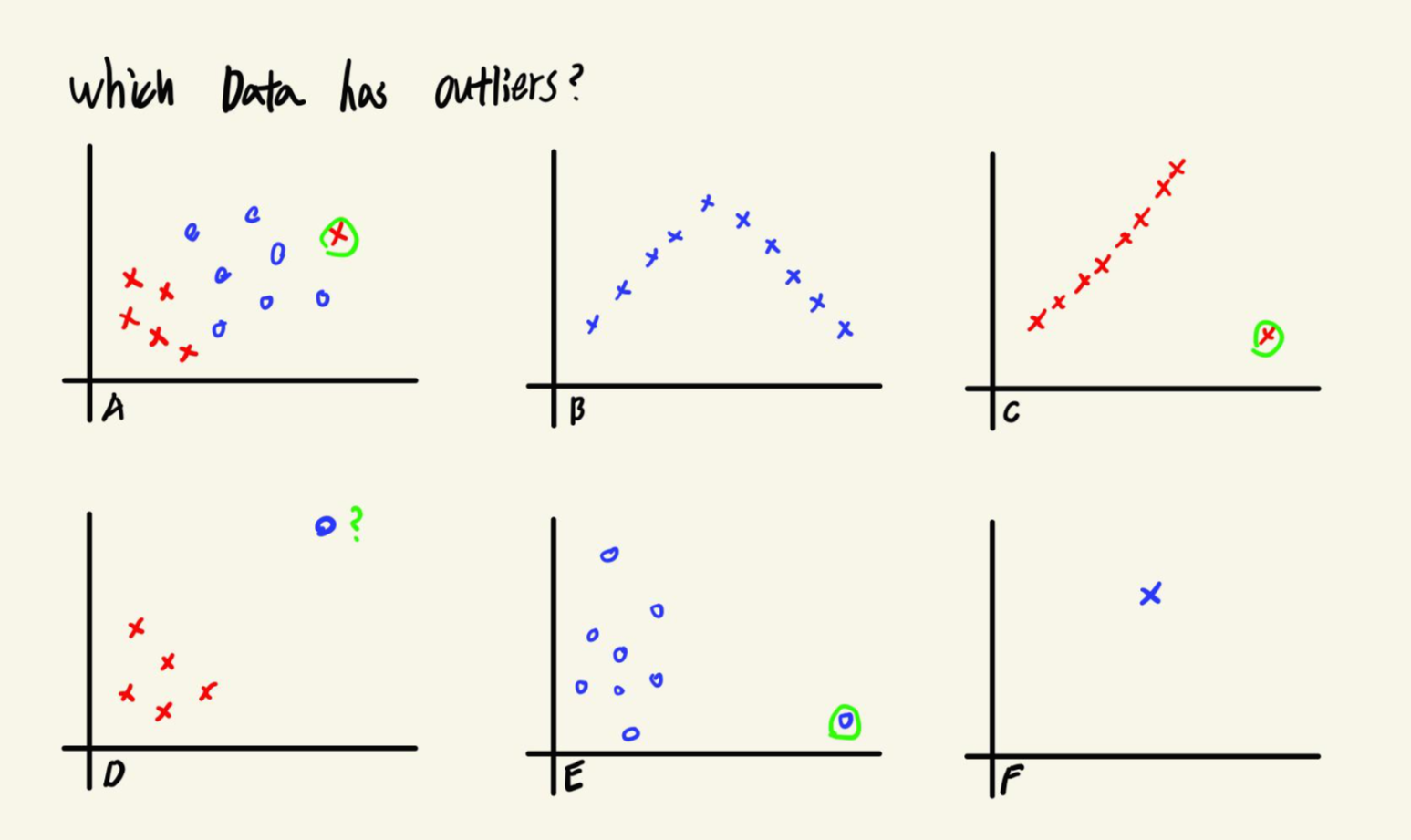
A - 대부분의 X와는 달리 O들과 비슷한 패턴을 보이므로 이상치라고 볼 수 있다고 합니다. 분류가 가능한 데이터라고 생각하는데, 다른 X들과 많이 차이나는 X값을 가지고 있는 경우를 이야기하고 싶었던 것 같습니다.
B - 이상치가 없는 데이터입니다.
C - 직선형태의 데이터에 하나의 데이터포인트가 튀어나와있습니다. 글의 처음에 예로 들었던 데이터와 비슷한 형태로, 하나의 데이터 포인트 때문에 모델의 결과가 크게 달라지는 경우로 보입니다.
D - 이는 강의를 준비하는분들끼리도 의견이 갈렸다고 합니다. 단순한 Classification 문제로 볼 수도 있고, 다른 데이터들과 동떨어져 있다는 점에서 이상치로 보는 분도 있다고 합니다. 개인적으로는 전자에 해당한다고 생각합니다.
E - 대부분 낮은 값을 가지는 x들에 반해 큰 x값을 갖는 데이터가 존재합니다. 응답을 잘못 기입,입력한 경우에 이런 형태가 나타날것이라고 생각해볼 수 있습니다.
F - 단순히 하나의 데이터 포인트만 존재합니다. 저 데이터가 곧 패턴입니다.

마지막은 Outlier를 다루는 것에 대해 이야기합니다.
먼저 모든 데이터로 모델을 Train 한 뒤, Outlier를 확인하여 제거하고, 다시 Train하는 과정을 이야기합니다.
경우에 따라 Outlier를 제거하고 Train하는 과정을 반복할 수 있다고 이야기합니다.
Outlier에 대해서 더 자세하게 이야기했으면 좋았을것 같은데, Introduction이라 그런지 개념적인 설명이 중심이라 조금 아쉬웠습니다.
'강의정리 > udacity - machine learning' 카테고리의 다른 글
| Intro to machine learning - (9) Feature Scaling (0) | 2021.01.21 |
|---|---|
| Intro to machine learning - (8) Clustering (0) | 2021.01.19 |
| Intro to machine learning - (6) Regression(2) (0) | 2021.01.15 |
| Intro to machine learning - (6) Regression(1) (0) | 2021.01.13 |
| Intro to machine learning - (5) Datasets and Questions (0) | 2021.01.11 |



