
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 주피터 노트북 테마
- pandas
- 딥러닝
- random forest
- 한빛미디어
- MySQL
- Machine Learning
- GitHub
- deep learning
- 데이터분석
- 경사하강법
- Python
- Git
- 주피터노트북
- feature scaling
- deeplearning
- jupytertheme
- ubuntu
- Linear Regression
- 회귀분석
- lol api
- 주피터노트북 커널 추가
- Udacity
- 모두를 위한 딥러닝
- 주피터노트북 커널 제거
- 주피터테마
- regression
- 주피터노트북 커널 목록
- 나는리뷰어다2021
- overfitting
- Today
- Total
유승훈
Intro to machine learning - (1) Naive Bayes 본문
Intro to machine learning - (1) Naive Bayes
seunghuni96 2020. 11. 4. 19:04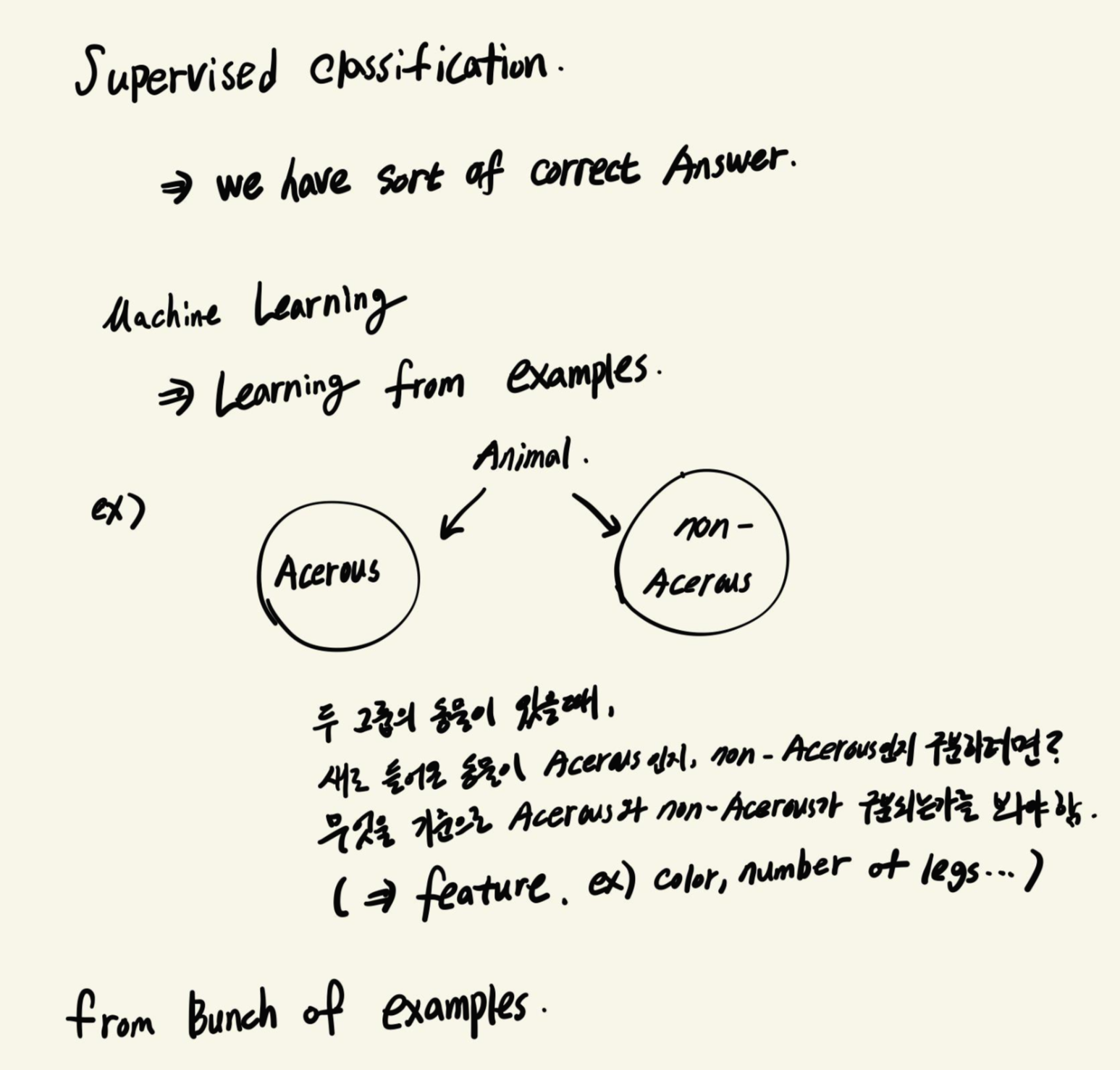
가지고 있는 동물들을 Acerous, Non-Acerous로 분류해두었다고 합시다.
여기에 새로운 동물이 들어와서 그룹 분류를 할 때, 이전에 어떤 기준으로 분류해두었는지를 봐야합니다.
분류기준은 동물의 색일수도 있고, 다리의 갯수, 뿔의 유무 등 다양한 것들이 있을 수 있습니다.

퀴즈.
네 가지 예시 중, 지도학습. 그 중에서도 분류문제에 해당하는 것은?
2번은 이전에 fraud - non fraud로 분류된 label 데이터가 없기 때문에 unsupervised learning에 해당합니다. 처음에는 fraud만 보고 classification 인 줄 알았는데, 틀리고 다시 보니 label이 없었습니다.
4번은 학습 스타일에 따라 학생들을 묶는 것이기 때문에 unsupervised learning, 그 중 clustering 문제에 해당합니다.
사실 제일 앞에 cluster만 봐도 supervised learning은 아님을 알 수 있습니다.

내가 노래를 들으면, 노래의 특징(강렬함, 템포, 장르, 가수의 성별)을 가지고 좋아하는 노래인지, 안좋아하는 노래인지를 판단합니다. 이때, 노래의 특징들은 변수(Feature, Variable)가 되고, 좋아하는가 / 좋아하지 않는가는 라벨(Label, Target)이 됩니다.

우리가 가진 변수들을 산점도(Scatter plot)로 그렸을때, 새로운 데이터가 들어오면 산점도의 위치에 따라 값을 짐작해볼 수 있습니다. 하지만 위치가 애매하다면? 빨간색일지 파란색일지 판단하기가 쉽지 않습니다.
여기서 Machine Learning이 하는것이 영역(Decision Surface)을 정해주는 것입니다. 이 영역을 기반으로 새로운 데이터가 어떤 값을 가질것인지를 정할 수 있습니다. 이 영역은 선형으로 분리되기도 하고, 비선형으로 분리되기도 합니다.


Naive Bayes는 많이 알려져 있는 베이즈 정리에서 출발합니다. 이는 조건부 확률을 계산하는 방법 중 하나인데,
P(A|B), 사건 B가 일어났을때 사건 A가 발생할 확률은
$P(A|B)={P(B|A)P(A) \over P(B)}$
이렇게 계산할 수 있습니다. B일때 A일 확률을 구하는 것인데, 기존 데이터를 기반으로 베이즈 정리를 활용하여 식을 정리하는 것입니다.
$P(cancer | test\_positive) = {P(cancer)P(test\_positive | cancer) \over P(test\_positive)}$
$P(not\_cancer | test\_positive) = {P(not\_cancer)P(test\_positive | not\_cancer) \over P(test\_positive)}$
두 식 모두 $P(test\_positive)$를 분모로 하고 있기 때문에 소거하고 계산할 수 있습니다.
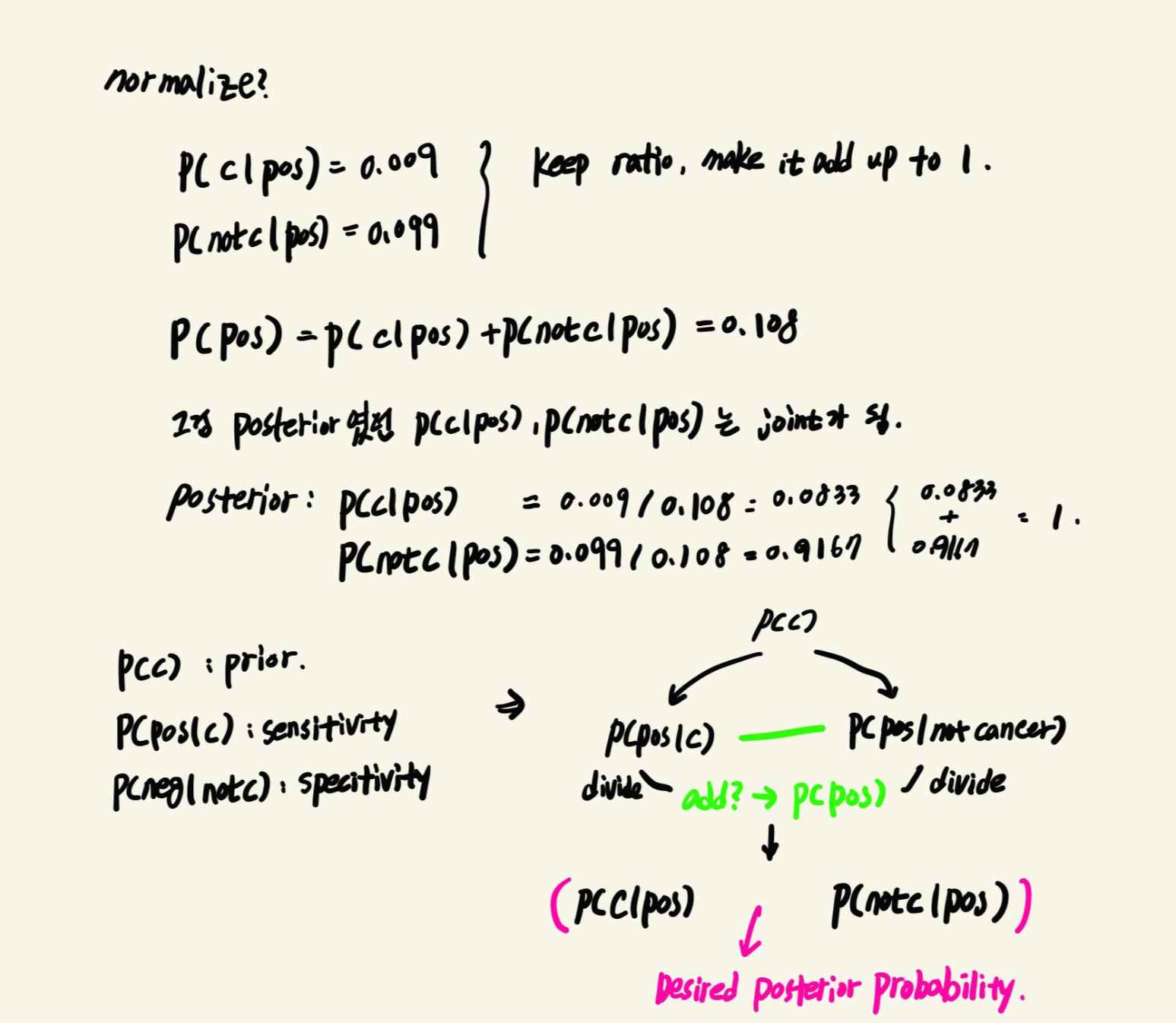
위의 식에서 계산된 확률을 Normalize하면, 전체를 1로 보고 확률을 계산할 수 있습니다.
여기서는 검사가 양성일때 암이 있을 확률은 8.33%, 암이 없을 확률은 91.67%로 나옵니다.

나이브 베이즈는 텍스트를 분류하는데도 사용될 수 있습니다.

"Naive" 라는 단어가 붙는 이유는, Target 예측에 사용되는 모든 변수들이 독립이라는 가정하에 돌아가기 때문입니다.
마지막에 모든 Machine Learning Algorithm들을 Black Box로 보는 것이 아니라, 어떻게 돌아가는지를 이해하고 내가 풀어야할 문제와 사용하는 데이터에 대한 이해를 기반으로 알고리즘을 잘 선택해서 사용해야한다는 말이 기억에 남습니다.
'강의정리 > udacity - machine learning' 카테고리의 다른 글
| Intro to machine learning - (6) Regression(1) (0) | 2021.01.13 |
|---|---|
| Intro to machine learning - (5) Datasets and Questions (0) | 2021.01.11 |
| Intro to machine learning - (4) Choose your own algorithm (0) | 2020.11.30 |
| Intro to machine learning - (3) Decision Tree (0) | 2020.11.17 |
| Intro to machine learning - (2) Support Vector Machine (0) | 2020.11.08 |



