
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- lol api
- 주피터노트북 커널 추가
- deeplearning
- MySQL
- overfitting
- random forest
- jupytertheme
- Linear Regression
- 딥러닝
- GitHub
- deep learning
- 한빛미디어
- 경사하강법
- Python
- ubuntu
- 나는리뷰어다2021
- 주피터 노트북 테마
- 주피터노트북
- 회귀분석
- Udacity
- feature scaling
- 주피터노트북 커널 목록
- regression
- 데이터분석
- Machine Learning
- 모두를 위한 딥러닝
- 주피터노트북 커널 제거
- Git
- 주피터테마
- pandas
- Today
- Total
유승훈
Python 연관규칙 분석 이해하기(2021 LCK Spring 벤픽 데이터) - (1) apriori, association_rule 본문
Python 연관규칙 분석 이해하기(2021 LCK Spring 벤픽 데이터) - (1) apriori, association_rule
seunghuni96 2021. 4. 26. 19:05Python에 Mlxtend라는 패키지가 있습니다. 데이터 분석을 위한 작업에 있어서 유용한 도구들이 있는 패키지입니다.
Home - mlxtend
From here you can search these documents. Enter your search terms below.
rasbt.github.io
개인적인 프로젝트를 하면서 이 패키지에 있는 연관규칙 함수를 쓰게 되었는데요, 공부하는 겸해서 API와 User Guide의 내용을 정리해두고자 합니다. 예시 데이터가 아니라 제가 개인적으로 프로젝트를 하고 있는 2021년 LCK Spring 시즌 진영별 벤/픽 데이터입니다.
- mlxtend.frequent_patterns.apriori
- mlxtend.frequent_patterns.association_rules
- mlxtend.frequent_patterns.fpgrowth
- mlxtend.frequent_patterns.fpmax
이렇게 네 개의 함수에 대해서 살펴보고자 합니다. 글을 작성하면서 활용할 데이터셋은
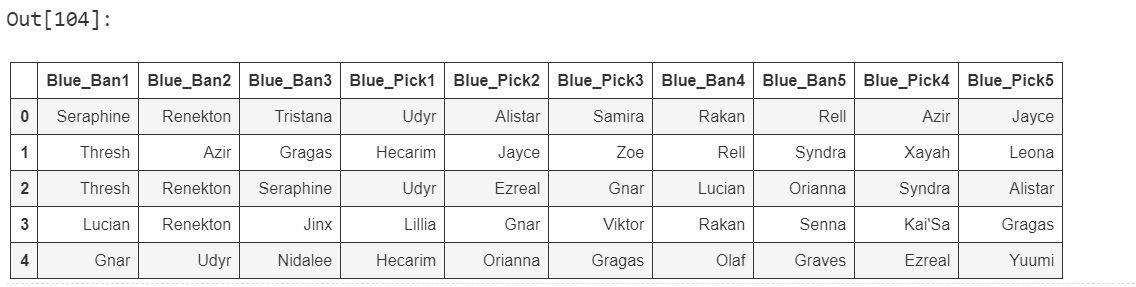

위와 같습니다. 시즌에서 진행된 모든 세트의 데이터입니다. 동일한 챔프를 벤하기도 하고, 픽하기도 했기 때문에 Ban 컬럼에 들어있는 데이터 앞에는 "Ban_"을, Pick 컬럼에 들어있는 데이터 앞에는 "Pick_"을 붙여주었습니다.
각 행이 한 세트에서 진행된 벤/픽이기 때문에, 하나의 장바구니로 생각하면 됩니다.

위와 같이 어떤 게임에서는 나르를 벤하고, 또 다른 게임에서는 나르를 픽했기 때문에 "Pick_Gnar", "Ban_Gnar"로 구분되어 있습니다.
apriori
- df : One-Hot Encoding 된 DataFrame을 Input으로 받습니다. mlxtend 패키지의 Encoder를 통해 데이터를 처리해줄 수 있습니다.
- min_support : 0과 1 사이의 숫자로 반환할 아이템 조합의 최소 지지도를 설정합니다. 지지도는 transactions_where_item(s)_occur / total_transactions라고 써있습니다. 어떤 아이템 A의 지지도를 아이템A의 등장횟수 / 전체 횟수로 생각하면 됩니다.
- use_colnames : True/False로 입력합니다. Apriori 함수의 결과 itemset을 Column number로 할 지, apriori에 입력한 DataFrame의 컬럼명으로 할 지를 정합니다. True일 경우 컬럼명을, False일 경우 숫자로 아이템 조합이 반환됩니다.
- max_len : int. 아이템 조합의 최대 개수를 입력합니다. 기본값인 None은 주어진 조건 하에서 가능한 모든 아이템 조합을 반환합니다.
어떤 식으로 전처리를 했는지 잠깐 설명하고 넘어가겠습니다.

select_cols는 제가 만들어서 쓴 함수입니다. Ban, Pick, Position 같은 컬럼을 한번에 가져올 수 있도록 작성한 함수입니다.

그 다음에는 mlxtend.preprocessing에 있는 TransactionEncoder를 사용했습니다. Sklearn에서 제공하는 다양한 Encoder나 Scaler들을 써보신 분들이라면 익숙하게 사용하실 수 있을 것 입니다. fit_transform으로 우리의 데이터를 apriori input 형식에 맞게 바꿔줍니다.

그 결과로 위와 같은 데이터를 얻게 됩니다. 이제 apriori 함수에 넣어서 결과를 보도록 합시다.

apriori 함수를 쓴 결과입니다. itemsets에 들어있는 item들이 많은 순대로 정렬했습니다. 89번 아이템과 함께 44번, 12번 아이템이 많이 벤픽에 등장한 것을 볼 수 있습니다. 하지만 아이템 번호로 되어 있기 때문에, 어떤 챔피언인지는 알 수가 없습니다. 아이템 번호가 아니라 컬럼명으로 결과를 받기 위해서는 use_colnames 옵션을 써줍니다.

use_colnames를 쓰니 어떤 챔피언인지, 벤을 했는지 픽을 했는지를 볼 수 있습니다. 카이사를 픽할 때 레넥톤과 나르를 많이 벤한 것을 볼 수 있습니다.

위와 같이 subset을 해 줄 수도 있습니다.
여기까지가 apriori에 대한 설명입니다. 그 다음으로는 association rule에 대해서 살펴보겠습니다.
association_rule
Rule Generation은 빈번 패턴 분석에서 많이 활용됩니다. 연관 규칙은 `X->Y` 형태의 함축적인 표현이라고 볼 수 있습니다. `X`와 `Y`는 disjoint itemsets, 즉 서로소 자료구조입니다. 각각 하나의 아이템을 가질 수도 있지만, 두개 이상의 아이템을 가질 수도 있습니다. 데이터와 관련한 강의나 세미나 같은 곳에서 한번쯤은 들어봤을법 한 "기저귀를 사는 사람은 맥주도 같이 사더라"같은 것이죠. 이 연관규칙을 평가하기 위해서 다양한 Metric들이 활용됩니다.
- df : association rule은 apriori, fpgrowth, fpmax의 결과로 만들어지는 "frequent itemsets"를 그 결과로 받습니다. 앞서 apriori 의 결과로 나왔던 ['support', 'itemsets'] 두 컬럼을 갖는 DataFrame이 "frequent itemsets"입니다.
- metric : 평가지표를 String으로 넣어줍니다. 기본값인 'confidence'이고, support_only가 True로 설정되면 이 값은 자동으로 'support로 설정됩니다. 'support', 'confidence', 'lift', 'leverage', 'conviction'이 입력될 수 있습니다.
- min_threshold : metric에 입력된 평가지표의 최소값을 입력해줍니다. 평가지표가 이 값을 넘어야만 결과로서 반환됩니다.
- support_only : 모든 다른 Metric Column은 NaN으로 두고, Support만을 계산합니다. 이는 두 가지 경우에 유용하게 활용될 수 있습니다.
a) 모든 Itemset에 대한 support 값을 가지고 있지 않은 경우
b) 다른 Metric들 필요없이 단순히 빠른 결과를 원하는 경우
명확히 해야 하는 것은, metric에 입력된 평가지표만이 반환되는 것이 아닙니다. 'support', 'confidence', 'lift', 'leverage', 'conviction' 모든 값이 결과 DataFrame에 계산되어 나타납니다.
User Guide에 정리된 Metric들을 간단하게 정리하면,

Support, 지지도는 연관규칙이 아니라 Itemset에 대해서 정의됩니다. Association Rule 알고리즘은 'Antecedent Support', 'Consequent Support', 'Support' 이렇게 세 가지의 Metric을 반환합니다.
- Antecedent Support는 Item A가 포함되는 비율
- Consequent Support는 Item C가 포함되는 비율
- Support는 A와 C 모두를 갖는 비율입니다.
Support는 데이터베이스에서 Itemset의 빈도에 대한 평가지표입니다. 지지도가 우리가 설정한 어떤 threshold 값보다 크다면, 우리는 이 Itemset을 "Frequent itemset", 즉 빈번하게 등장하는 itemset인 것으로 평가합니다. 하지만 downward closure property 때문에 "Frequent itemset"의 모든 Subset도 빈번하게 등장하는 것으로 판단합니다.
여기서 Downward Closure Property는 무엇일까요?
어떤 Itemset K가 있다고 합시다. K는 {3,6,9} 세 가지 아이템으로 구성되어 있습니다. 이 Itemset이 데이터베이스에서 적게 나왔다고 합시다. 그러면 이 K를 포함하는 슈퍼패턴인 J는, 하나 예를 들면 {1,3,6,9}가 있죠. 이 J가 나오는 경우의 수는 K가 나오는 수와 같거나 그 보다 적을 수 밖에 없습니다.
즉, 어떤 Itemset이 잘 등장하지 않는다는 것을 알게 되면, 그 패턴의 모든 슈퍼패턴도 잘 등장하지 않는다는 것을 알 수 있습니다. 이런 상황에서 더 깊게 들어가지 않고 해당 패턴을 모두 잘라내는 것이 안티모노톤의 속성, Downward Closure Property입니다.

Confidence는 전반부 Item인 A가 등장할 때, A,C조합이 얼마나 같이 등장하는지를 나타내는 확률입니다. A->C의 Confidence와 C->A의 Confidence는 다르다는 것을 기억해야 합니다. Confidence가 최대값인 1을 갖는다면, Item A가 등장할 때 무조건 C가 같이 등장한다는 것을 의미합니다.

Lift는 A와 C가 독립이라는 가정에 비해 A,C가 얼마나 자주 같이 등장하는지를 나타냅니다. 만약 A,C가 독립이라면, Lift는 1이 됩니다.

Leverage는 A와 C가 같이 등장하는 빈도와 A와 C가 독립일때 같이 등장할 기대빈도의 차이를 나타냅니다. 만약 A와 C가 독립이라면, Leverage는 0입니다.

높은 Conviction 값은 후반부 아이템(C)이 전반부 아이템(A)에 높은 의존을 보이고 있다는 것을 의미합니다. 예를 들어서, A와 C가 같이 등장하는 경우, Confidence가 1이 되는데, 이 때 분모가 0이 되고, Conviction은 'inf'가 됩니다. Lift와 비슷하게, 전반부와 후반부의 아이템들이 독립이면, Conviction은 1이 됩니다.
그럼 association_rules의 결과를 한번 보도록 합시다.
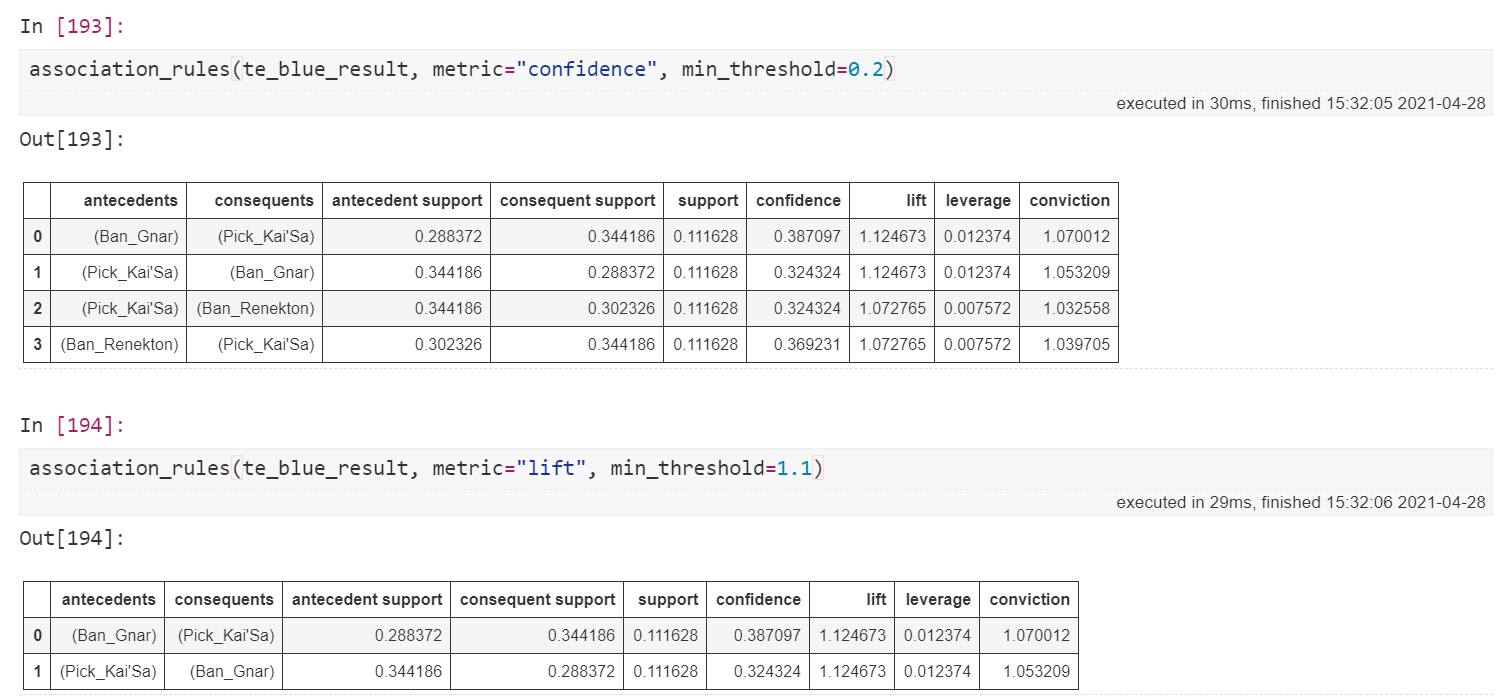
metric에 입력된 평가 지표를 min_threshold 이상의 값을 가지는 Item 조합을 기준으로 볼 수 있습니다. 결과는 우리가 흔히 접하는 DataFrame과 동일하기 때문에, 함수에 입력해주는 값 외에도 Subset을 통해 더 자세히 살펴볼 수 있습니다.
마지막으로 support_only에 대해서 정리하고 글을 마무리하고자 합니다.

예를 들어, 위와 같은 DataFrame을 association_rule에 넣는다고 해 봅시다. 이는 Itemset들의 각 Item들에 대한 support는 가지고 있지 않습니다. 이는 Metric들을 계산할 때 문제가 됩니다.
예를 들어, 176->177의 Confidence를 구한다고 해 봅시다. 계산할 때 176->177의 support와 176의 support 두 개가 필요합니다. 우리가 전자, 분자에 해당하는 수치는 가지고 있지만, 분모에 대해서는 아는게 없습니다. 단지 176->177의 support인 0.253623 보다는 크다는 것 밖에는요.
이처럼 모든 Metric을 계산할 수 없는 경우에, support_only=True 옵션을 통해 주어진 규칙들에 대한 support만을 계산할 수 있습니다.

이렇게 support 컬럼을 제외하고는 모든 값을 NaN으로 반환합니다.
이번 글에서는 mlxtend 패키지의 apriori와 association rule에 대해서 알아보았습니다. 이외에도 mlxtend에는 fpgrowth와 fpmax 함수가 있습니다. 이 두 가지에 대해서는 다음 글에서 알아보도록 하겠습니다.
'languages > Python' 카테고리의 다른 글
| Riot API 사용하기 - (1) 최상위티어 유저 가져오기. (2) | 2021.10.07 |
|---|---|
| Jupyter notebook 커스터마이징(theme, font..) (0) | 2021.06.21 |
| Selenium을 활용한 멜론 플레이리스트 캡처 자동화(feat. 주다사) (0) | 2021.03.23 |
| TypeError: 'float' object cannot be interpreted as an integer (2) | 2021.01.23 |
| 카카오 API를 활용한 좌표->주소 변환하기(Python) (0) | 2020.12.21 |



